Appearance
LAD-GNN论文导读与随思
主讲人:kiyotakali
论文标题
Label Attentive Distillation for GNN-Based Graph Classification
论文链接
论文代码
Readme里承诺是Code will be available after NeurIPS2024 ddl 🥲,anyway,可以先了解一下idea XiaobinHong/LAD-GNN: The source code of LAD-GNN. (github.com)
简介:
该文首先提出一个观点:过去传统的GNN在汇聚邻居节点特征时候并没有考虑图标签信息,生成的node embedding和label embedding的差距较大,同时提出了模型LAD-GNN(Label-Attentive Distillation Graph Neural Networks),具体见下图
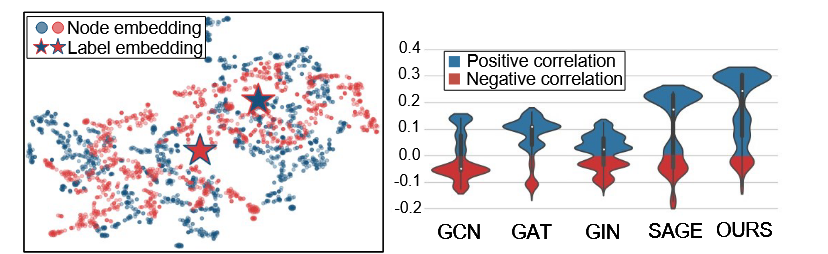
为了解决上述问题,该文提出了一种名为LAD-GNN标签关注蒸馏方法,主要方法是采用基于蒸馏的方法来交替训练教师模型和学生模型:
- 教师模型:通过标签编码器和注意力机制将node embedding 与label embedding进行融合,生成理想的嵌入向量。
- 学生模型: 上述教师模型最终的理想嵌入向量被用作监督,通过交叉熵和MSE损失函数的结合训练学生模型。
方法介绍
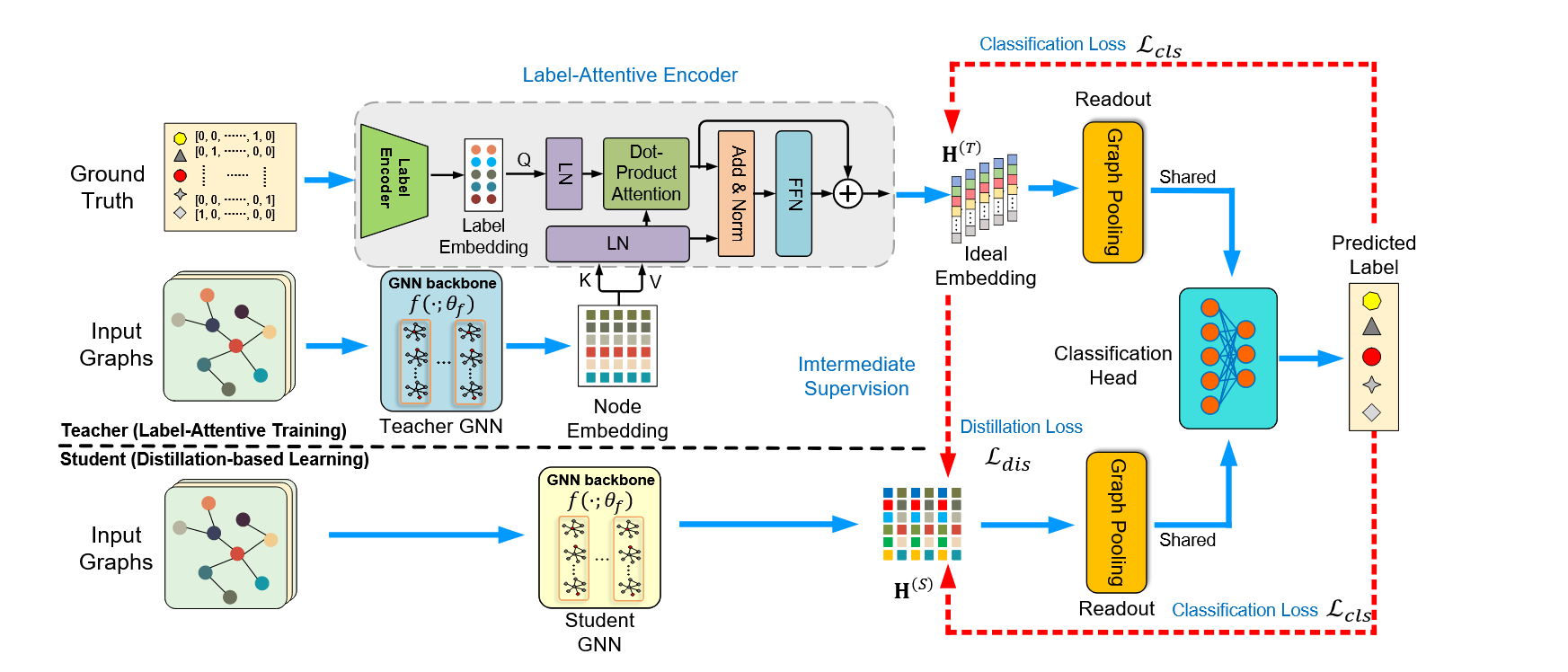
首先,对于上图中上半部分,文中提出了一种基于标签注意力机制的教师模型训练方法。具体来说分为以下几步:
- 将Ground-truth labels输入标签编码器得到latent embedding,在论文中作者建议使用多层感知机
- 使用注意力机制将label embedding 与 TeacherGNN得到的node embedding进行融合得到ideal embedding,和transformer的架构比较相似。具体公式如下,
是由label encoder生成的标签嵌入向量, 是由GNN backbone生成的节点嵌入向量, 是标签嵌入投影, 以及 是节点标签嵌入投影,并且 是注意力温度系数
- 将上述环节得到的ideal embedding经过reandout函数(graph pooling) ,然后经过共享的分类头输出预测标签
,损失函数是交叉熵。
然后,对于上图中的下半部分,文中提出了基于蒸馏的学生模型,学生模型通过知识蒸馏向教师模型学习,并与教师模型共享classification head。
- 首先将图输入学生GNN中获得node embedding
- 然后在教师模型训练收敛之后,使用教师模型训练得到的理想嵌入监督知道学生GNN的学习,其实是通过类似蒸馏的方法增强学生GNN的节点嵌入,这一部分类似蒸馏的方式是通过最小化MSE损失函数得到的。
- 从整体上来看学生模型使用和教师模型相同的训练样本进行训练,并且损失函数为
模型伪代码如下: 
实验
作者使用十折交叉验证评估模型性能,并且所有数据集按照0.1,0.1,0.1划分为训练集,验证集,测试集
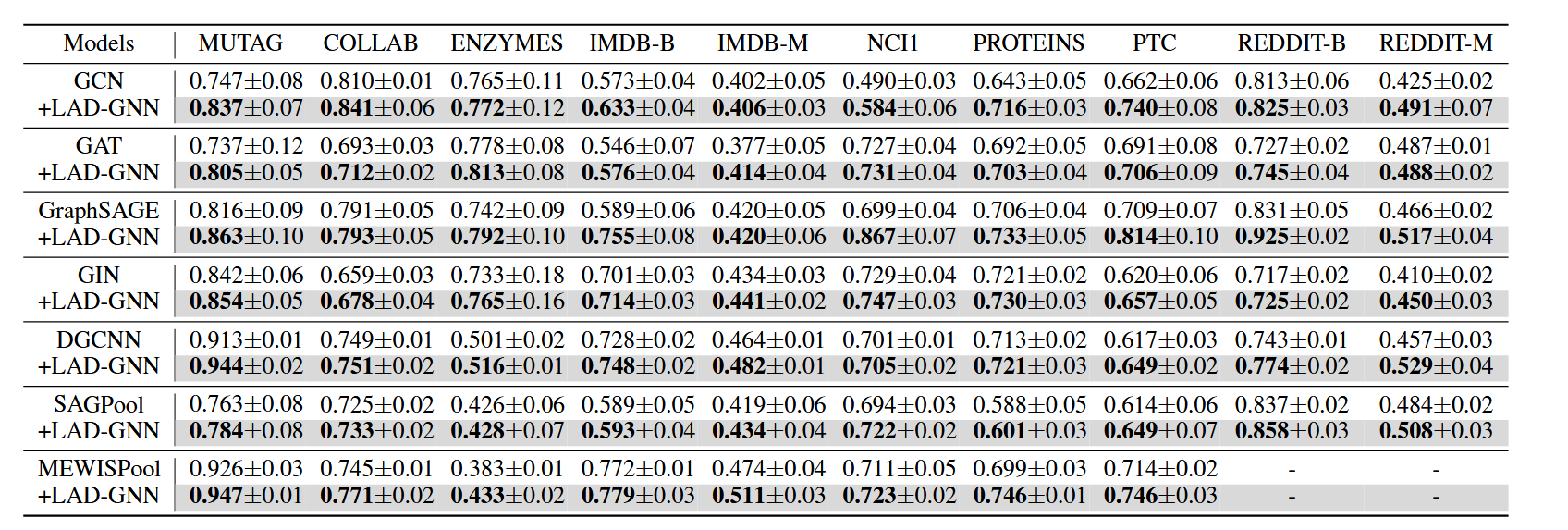
以下是作者的测试结果 首先是不同模型引入LAD-GNN之后的准确率变化情况
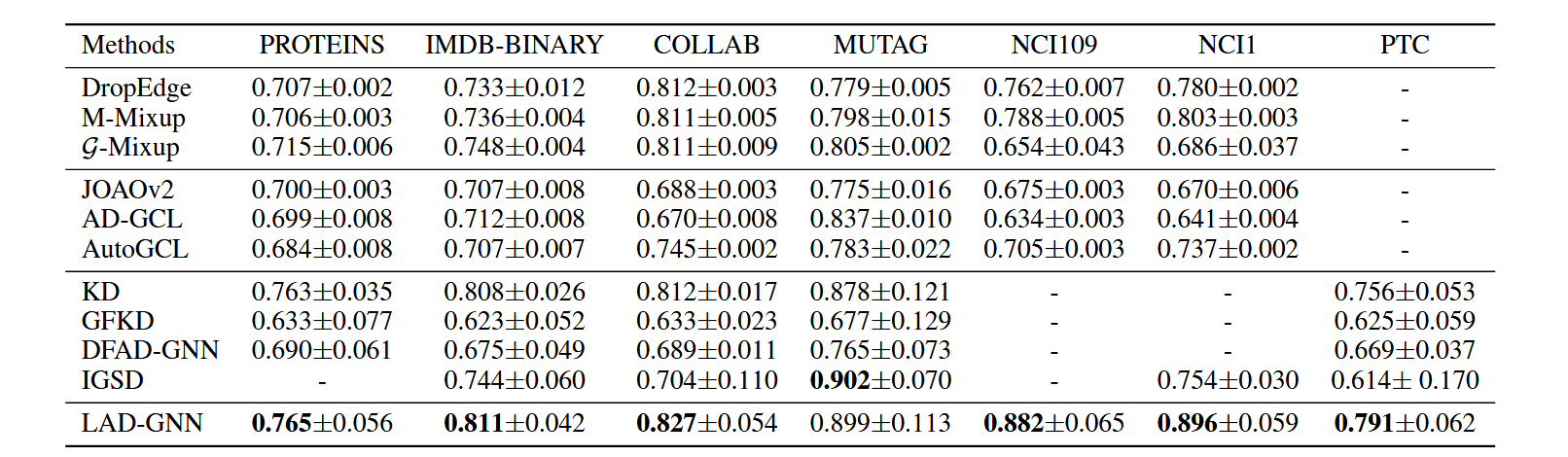
然后是LAD-GNN与不同模型之间的比较
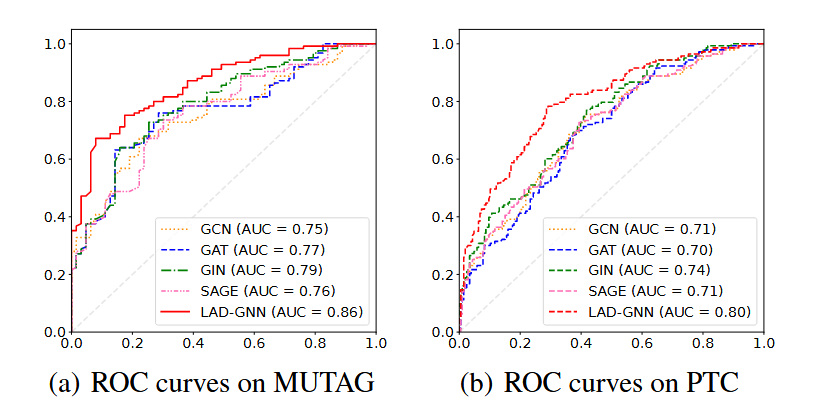
以及LAD-DNN与其他模型的ROC曲线
总结
刚开始读这篇论文时候感觉大为震撼,不管是学生-老师的模型架构还是引入label-encoder得到label-embedding再与node-embedding利用注意力机制结合的思路都让我眼前一亮,后来发现还是自己paper读得少并且局限在原来很小的一个领域,学生-老师模型好像在蒸馏领域挺常用的,encoder得到embedding再与其他embedding通过注意力机制融合并更新label-embedding以及得到二者融合的所谓ideal embedding其实至少在cv领域好像还有挺多类似的方法,本文主要贡献其实可能并不是后来复杂的模型图,而是一开始想要将label embedding 与 node embedding相结合来提高下游任务准确率的这样一个想法。Anyway,it works!虽然很多方法可能已经用得很多,但是在这个模型中使用起来仍然很合适并且取得了不错的效果。
憨憨困惑:
文章中特别强调了使用学生GNN进行图分类任务时是没有标签输入的,但是损失函数确实有交叉熵,感觉这里可能没有解释清楚?
教师和学生使用训练集是一样的,并且这个使用场景局限于分类任务,那么为什么不直接使用教师模型进行分类预测呢?我姑且认为是node embedding在与label embedding在融合的时候丢失了原来的一部分信息,训练效果可能并不是很好,所以需要重新训练新的node embedding来从ideal embedding中学习有关类别的信息,但是这样是否会带来一个问题:只是简单通过MSE与交叉熵损失函数的结合看似一边使得学生从老师那边学习得到信息,一边又根据与真实类别的比较剔除学到的与类别无关的噪声信息,但是个人认为如何衡量这个学习-剔除噪声的方式需要一个标准进行有效的衡量,比方说信息论?
参考
Label Attentive Distillation for GNN-Based Graph Classification:Label Attentive Distillation for GNN-Based Graph Classification | Proceedings of the AAAI Conference on Artificial Intelligence