Appearance
图神经网络(GNN)简介
主讲人:kiyotakali
GNN能做什么(和CNN相比)
近十年来(从2012年AlexNet开始计算),深度学习在计算机视觉(CV)和自然语言处理(NLP)等领域得到的长足的发展,深度神经网络对于图像和文字等欧几里得数据(Euclidean data)可以进行较好的处理
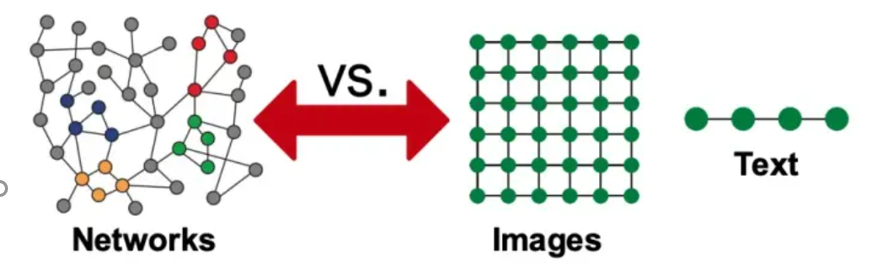
但是现实世界是复杂的,如社交网络,一个人的朋友数量是不固定的,也很难排个顺序,这类复杂的非欧几里得数据(non-Euclidean),没有上下左右,没有顺序,没有坐标参考点,难以用方方正正的(grid-like)矩阵/张量表示,为了把不规则的脚(非欧数据)穿进标准的鞋(神经网络)里,之前干了不少削足适履的事,效果不太好,于是,问题变成了:能否设计一种新的鞋,使它能适合不规则的脚呢?
非欧数据的场景很多,除了上面提到的社交网络,其他例子如:计算机网络,病毒传播路径,交通运输网络(地铁网络),食物链,粒子网络,(生物)神经网络,基因控制网络,分子结构,知识图谱,推荐系统,论文引用网络等等。这些场景的非欧数据用图(Graph)来表达是最合适的,但是,经典的深度学习网络(ANN,CNN,RNN)却难以处理这些非欧数据,于是,图神经网络(GNN)应运而生,GNN以图作为输入,输出各种下游任务的预测结果。
下游任务包括但不限于: •节点分类:预测某一节点的类型 •边预测:预测两个节点之间是否存在边 •社区预测:识别密集连接的节点所形成的簇 •网络相似性: 两个(子)网络是否相似
NN的特性
本文主要以CNN为例,介绍GNN中三个核心思想——局部性(Locality)、汇聚(Aggregation)、组合(composition)
CNN的介绍
CNN的本质是将一个像素和其周围像素值通过卷积核进行汇聚,经过组合多层卷积结果后生成高层特征向量,这个向量包含图像多个特征,为下游任务(分类预测,聚类等)提供基础。 在上述任务中,局部性体现在卷积核对一个像素周围像素进行处理,实现全图范围的权值共享,同时卷积参数量远小于全连接神经网络,汇聚体现在一个像素周围像素参与卷积核的点积运算,具体如下图所示
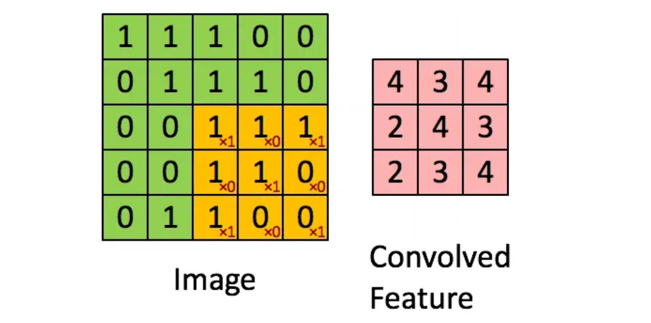
经过多次卷积和汇聚,最后生成特征向量()上图粉色部分向量表示特征,可以作为下游任务算法的输入 而对于局部性的解释个人认为上述卷积过程中一个像素点的周围像素值参与卷积决定新的特征向量,影响到当前向量值 其实在RNN中上述三个核心思想也有类似体现,在此不过多赘述
GNN-节点特征学习
首先,受Word2Vec启发,我们希望能够实现能够通过一个函数接受输入图作为参数,输出所有节点对应的嵌入向量,同时基于图的性质(根据相似性的假设,存在边的节点是比较相似的,比方说社交网络中你和你的朋友相似度会比较高,这也是我发现我和我朋友经常接收到一样的推送的原因之一)我们希望在图中临近的点对应的特征向量之间也能够比较接近(可以使用预先相似度来衡量节点向量之间的相似度,也就是接近程度)
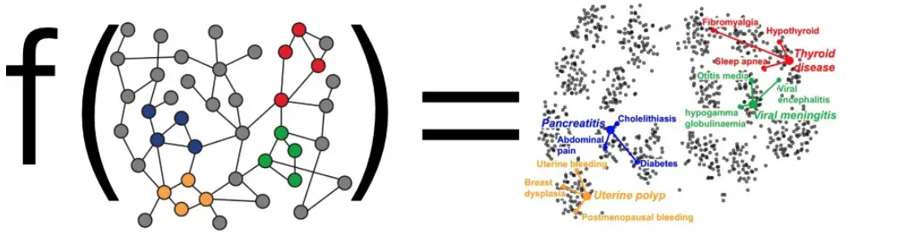
而对于图中某一个具体的节点v,在训练网络时以节点v作为输出,输出u的n维特征表示
消息传递
GNN中的节点特征是通过多轮的邻居消息扩散,也就是消息传递(Message Passing) 来计算和更新的,其实在社交网络中的话就相当于是通过你周边的朋友以及朋友的朋友等等来更加客观的了解你是什么样的一个人,而不只是局限于你自身提供的信息。
在经过一定轮次的消息传递之后,节点的特征值会趋于收敛,然后再进行更新,特征值也保持不变。而类似的思想在PageRank中其实也有体现。
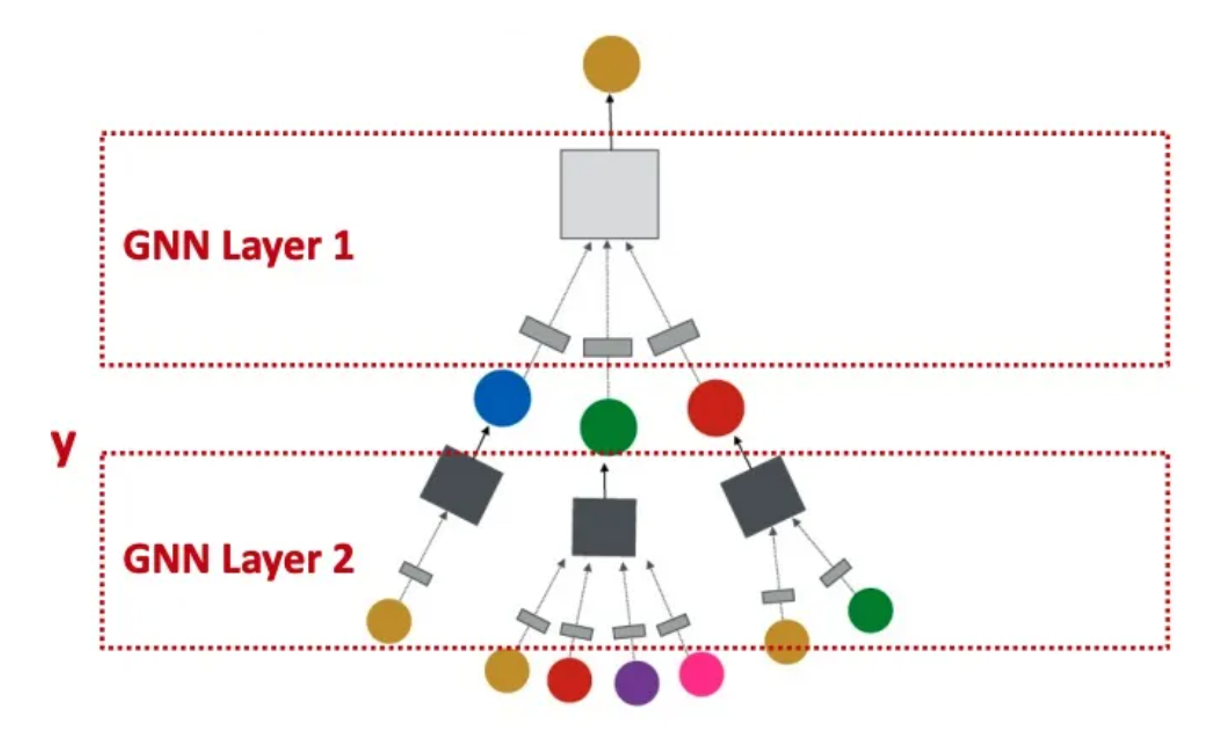
在大致了解了何为消息传递之后,我们来详细聊一聊他的具体实现。
- 首先节点向周围所有的邻居节点发出消息(节点自身在这一层的特征表示)
- 然后该节点从周围节点接收消息并更新自身的特征表示
按照上述逻辑来说,在k轮消息传递之后,节点就融合了从它出发距离小于等于k的所有节点的信息,这其实和之前提到的CNN以及RNN类似,消息传递层数的增加类似于CNN中卷积层的增多。
在这里插个题外话,在CNN中我们已经实现了具有较高准确率的深层网络,但是在GNN中目前消息传递轮数还不能太多(也就是卷积层数量比较有限),个人认为一方面和不够完善的消息传递和汇聚机制有关(比方说GCN),还有一方面可能我们也确实不一定需要卷积层特别多?比方说如果我们把地球上所有人按照社交关系相连,根据一个比较出名但不一定特别正确的假设:你与任何一个人社交关系之间相隔不超过6个人,那么我们发现其实当消息传递达到7轮的时候我们已经链接到世界上每一个人了,而根据之前提到的节点特征值保持不变的原则,如果我们既要汇聚世界上所有人的信息又要令特征值不变,那么我们可能只能提取出一个特征:这个节点代表一个人类,这显然不是我们想要的。
节点嵌入
GNN的深度可以是任意的(这里指可以认为指定,只不过太深的话效果不一定好),每层的节点都可以有自身的嵌入向量,在0层节点的嵌入向量来源于自身的特征,而第一层节点的特征向量来源于邻居节点的第0层向量和自身的第0层嵌入向量,也就是距离为1跳(1-hop)的节点,比方说下图Layer-1中节点B的嵌入向量融合了Layer-0中节点A和C的嵌入向量,并作为Layer-2中节点A的特征向量的一部分输入。
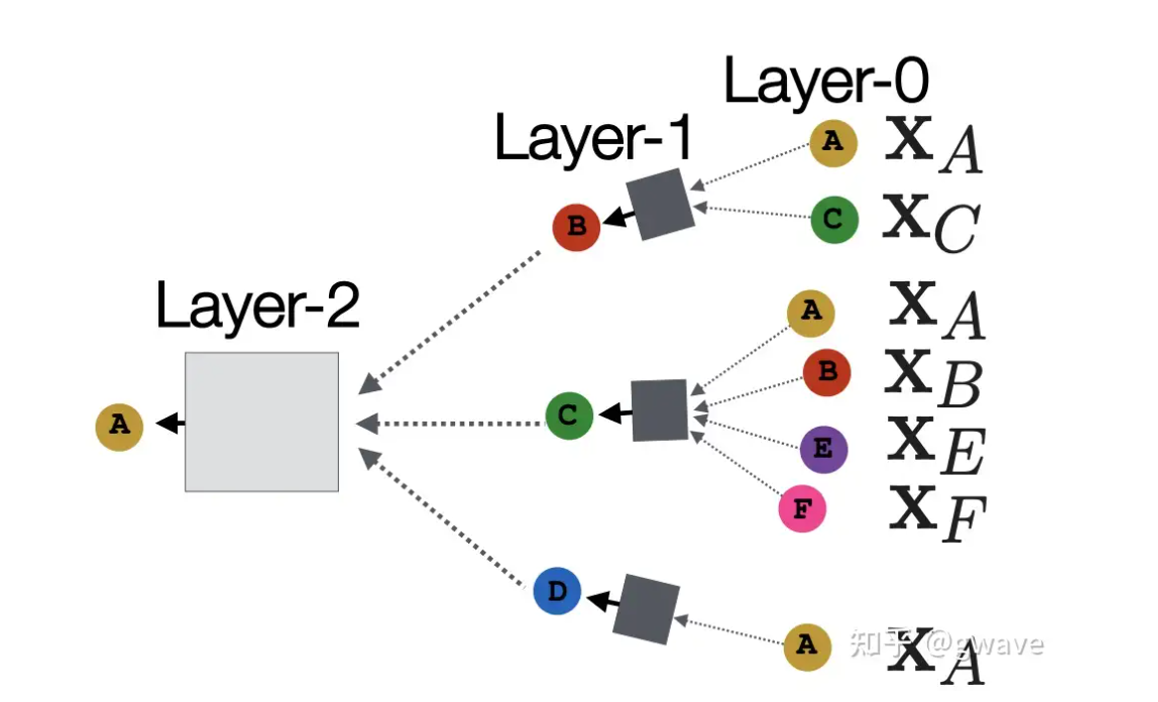
最后可以根据公式加深一下理解
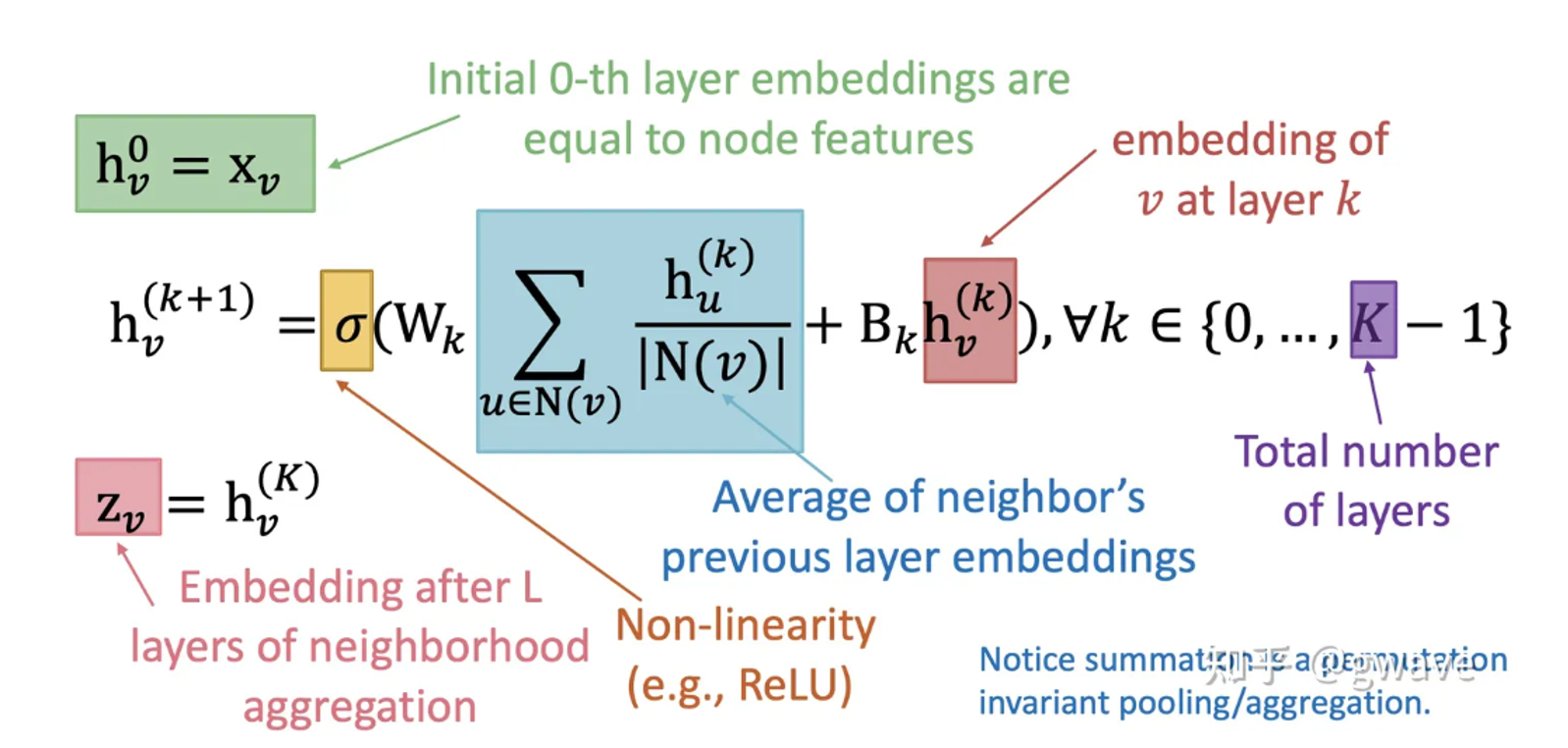
个人感觉这个公式标注都很详细,应该不用过多赘述
Code Sample
格式可能有点乱,具体的话可以访问(https://github.com/kiyotakali/GNN_review)查看GCN示例代码
python
class GCN(nn.Module):
""" 2 Layer Graph Convolutional Network.
Parameters
----------
nfeat : int
size of input feature dimension
nhid : int
number of hidden units
nclass : int
size of output dimension
dropout : float
dropout rate for GCN
lr : float
learning rate for GCN
weight_decay : float
weight decay coefficient (l2 normalization) for GCN. When `with_relu` is True, `weight_decay` will be set to 0.
with_relu : bool
whether to use relu activation function. If False, GCN will be linearized.
with_bias: bool
whether to include bias term in GCN weights.
device: str
'cpu' or 'cuda'.
Examples
--------
We can first load dataset and then train GCN.
>>> from deeprobust.graph.data import Dataset
>>> from deeprobust.graph.defense import GCN
>>> data = Dataset(root='/tmp/', name='cora')
>>> adj, features, labels = data.adj, data.features, data.labels
>>> idx_train, idx_val, idx_test = data.idx_train, data.idx_val, data.idx_test
>>> gcn = GCN(nfeat=features.shape[1],
nhid=16,
nclass=labels.max().item() + 1,
dropout=0.5, device='cpu')
>>> gcn = gcn.to('cpu')
>>> gcn.fit(features, adj, labels, idx_train) # train without earlystopping
>>> gcn.fit(features, adj, labels, idx_train, idx_val, patience=30) # train with earlystopping
"""
def __init__(self, nfeat, nhid, nclass, dropout=0.5, lr=0.01, weight_decay=5e-4, with_relu=True, with_bias=True,
self_loop=True, device=None):
super(GCN, self).__init__()
assert device is not None, "Please specify 'device'!"
self.device = device
self.nfeat = nfeat
self.hidden_sizes = [nhid]
self.nclass = nclass
self.gc1 = GCNConv(nfeat, nhid, bias=with_bias, add_self_loops=self_loop)
self.gc2 = GCNConv(nhid, nclass, bias=with_bias, add_self_loops=self_loop)
self.dropout = dropout
self.lr = lr
if not with_relu:
self.weight_decay = 0
else:
self.weight_decay = weight_decay
self.with_relu = with_relu
self.with_bias = with_bias
self.output = None
self.best_model = None
self.best_output = None
self.edge_index = None
self.edge_weight = None
self.features = None
def forward(self, x, edge_index, edge_weight):
if self.with_relu:
x = F.relu(self.gc1(x, edge_index, edge_weight))
else:
x = self.gc1(x, edge_index, edge_weight)
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, edge_index, edge_weight)
return x
def initialize(self):
"""Initialize parameters of GCN.
"""
self.gc1.reset_parameters()
self.gc2.reset_parameters()
def fit(self, name, features, adj, labels, idx_train, ganjing, idx_val=None, train_iters=200, initialize=True, verbose=False,
**kwargs):
"""Train the gcn model, when idx_val is not None, pick the best model according to the validation loss.
Parameters
----------
features :
node features
adj :
the adjacency matrix. The format could be torch.tensor or scipy matrix
labels :
node labels
idx_train :
node training indices
idx_val :
node validation indices. If not given (None), GCN training process will not adpot early stopping
train_iters : int
number of training epochs
initialize : bool
whether to initialize parameters before training
verbose : bool
whether to show verbose logs
normalize : bool
whether to normalize the input adjacency matrix.
patience : int
patience for early stopping, only valid when `idx_val` is given
"""
self.ganjing = ganjing
if initialize:
self.initialize()
if (name == 'ogbn-arxiv'):
self.edge_index = torch.LongTensor(adj)
self.edge_weight = torch.ones(adj.shape[1])
else:
self.edge_index, self.edge_weight = from_scipy_sparse_matrix(adj)
self.edge_index = self.edge_index.to(self.device)
self.edge_index, self.edge_weight = self.edge_index.to(
self.device
), self.edge_weight.float().to(self.device)
if sp.issparse(features):
features = utils.sparse_mx_to_torch_sparse_tensor(features).to_dense().float()
else:
features = torch.FloatTensor(np.array(features))
self.features = features.to(self.device)
self.labels = torch.LongTensor(np.array(labels)).to(self.device)
if idx_val is None:
self._train_without_val(self.labels, idx_train, train_iters, verbose)
else:
print(self.edge_index.shape)
print(self.features.shape)
self._train_with_val(self.labels, idx_train, idx_val, train_iters, verbose)
common_count = torch.sum(self.labels[idx_train].cpu() == torch.tensor(self.ganjing[idx_train]))
max_indices = torch.argmax(self.output[idx_train], dim=1)
predicted_numbers = max_indices.tolist()
common_count = torch.sum(torch.tensor(predicted_numbers) == torch.tensor(self.ganjing[idx_train]))
def _train_without_val(self, labels, idx_train, train_iters, verbose):
self.train()
optimizer = optim.Adam(self.parameters(), lr=self.lr, weight_decay=self.weight_decay)
for i in range(train_iters):
optimizer.zero_grad()
output = self.forward(self.features, self.edge_index, self.edge_weight)
loss_train = F.cross_entropy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()
if verbose and i % 10 == 0:
print('Epoch {}, training loss: {}'.format(i, loss_train.item()))
self.eval()
output = self.forward(self.features, self.edge_index, self.edge_weight)
self.output = output
def _train_with_val(self, labels, idx_train, idx_val, train_iters, verbose):
if verbose:
print('=== training gcn model ===')
optimizer = optim.Adam(self.parameters(), lr=self.lr, weight_decay=self.weight_decay)
best_loss_val = 100
best_acc_val = 0
for i in range(train_iters):
self.train()
optimizer.zero_grad()
output = self.forward(self.features, self.edge_index, self.edge_weight)
loss_train = F.cross_entropy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()
if verbose and i % 10 == 0:
print('Epoch {}, training loss: {}'.format(i, loss_train.item()))
self.eval()
output = self.forward(self.features, self.edge_index, self.edge_weight)
loss_val = F.cross_entropy(output[idx_val], labels[idx_val])
acc_val = utils.accuracy(output[idx_val], labels[idx_val])
if acc_val > best_acc_val:
best_acc_val = acc_val
self.output = output
weights = deepcopy(self.state_dict())
if verbose:
print('=== picking the best model according to the performance on validation ===')
self.load_state_dict(weights)
def test(self, idx_test):
"""Evaluate GCN performance on test set.
Parameters
----------
idx_test :
node testing indices
"""
self.eval()
output = self.forward(self.features, self.edge_index, self.edge_weight)
print('output,',output,output.shape,output.dtype)
print('label type,',self.labels.dtype)
loss_test = F.cross_entropy(output[idx_test], self.labels[idx_test])
acc_test = accuracy(output[idx_test], self.labels[idx_test])
print("\tGCN classifier results:",
"loss= {:.4f}".format(loss_test.item()),
"accuracy= {:.4f}".format(acc_test.item()))
return float(acc_test)引用
本文引用了Stanford CS224W课程相关信息以及[https://zhuanlan.zhihu.com/p/463666907?utm_psn=1767659196764721152]上述网站文章,同时强烈推荐该文章作者,至少在GNN方面他对几个常用模型的介绍写得极其通俗易懂 同时他的GNN实战示例[https://zhuanlan.zhihu.com/p/504978470?utm_psn=1767659249079975936]也能帮助大家从代码层面深入了解GNN基本模型,而且亲测git clone后配好环境直接可以跑!