Appearance
情感计算:语音分析
1. 概念
- The phrase ‘‘Affective computing’’ was created by Rosalind Picard, describing it as a computer systems study field concerned with the recognition and response to human emotions.
2. 分类方式
快乐、悲伤、恐惧、愤怒、厌恶和惊讶(六种基本情绪)
这是最主流用的标签,也是比较简单的
Feidakis 等人提出了一个由66种不同情绪组成的情绪分类模型,分为两组:十种基本情绪(愤怒、期待、不信任、恐惧、快乐、喜悦、爱、悲伤、惊讶、信任)和56种次级情绪。
在二维平面上表现情绪(valence & arousal)
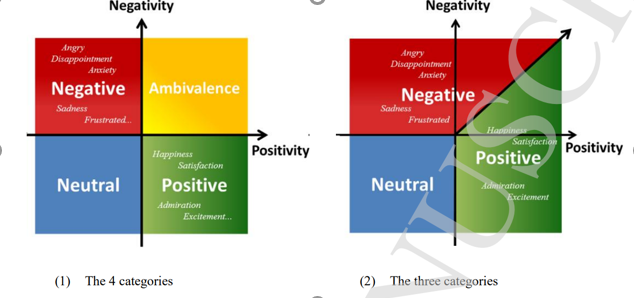
- 能更准确的描述标签信息
- 没有被数据集广泛采纳与使用
3. 常见数据来源
- Facial expressions
- Body gestures and postures
- Voice, audio, or speech
- Physiological signals.
- Textual data
4. 音频领域的情感计算
传统方法:
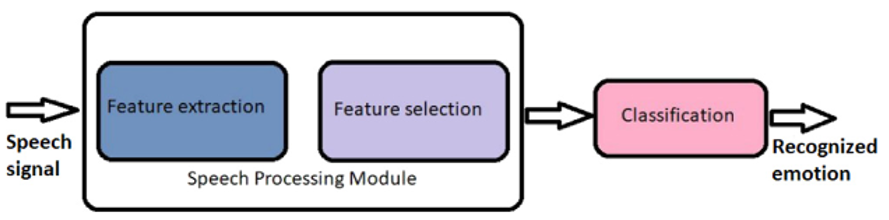
- 信号预处理:包括去噪和分段处理,以识别有意义的信号单元并去除输入信号的噪声
- 特征提取:特征提取与选择
- 分类:SVM,GMM和HMMs
DL方法
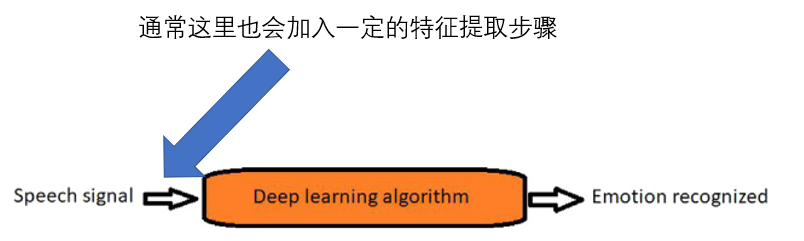
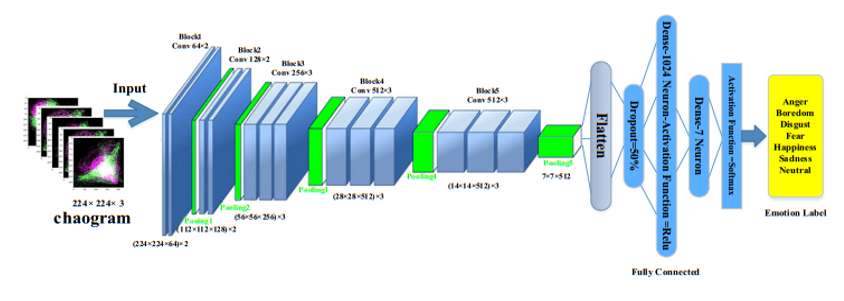
主要用的还是CNN,LSTM,DBN,RNN和他们的组合
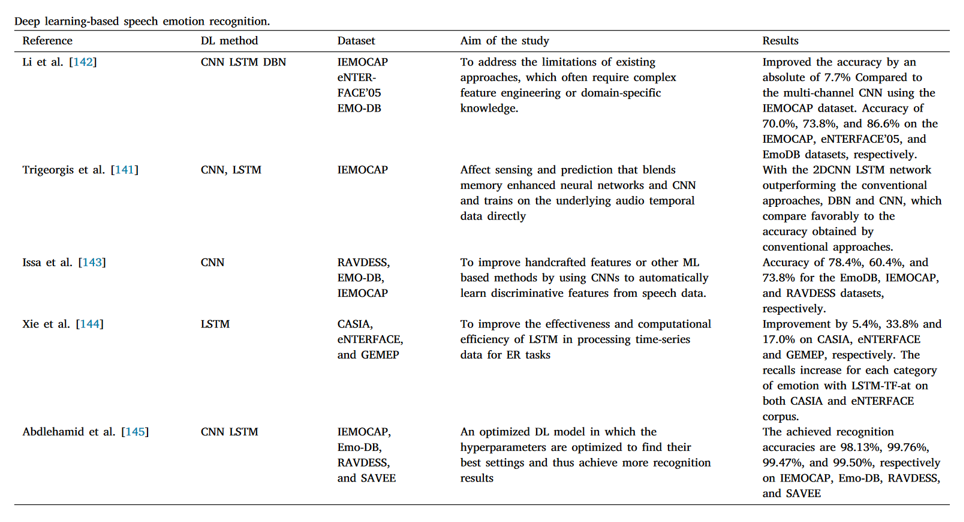
常用数据集
5. 音频预处理
频谱?相位谱?时域?频域?
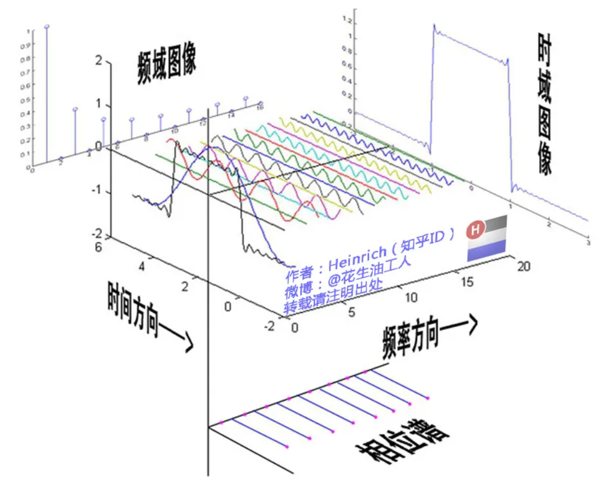
去噪
为什么能去噪?
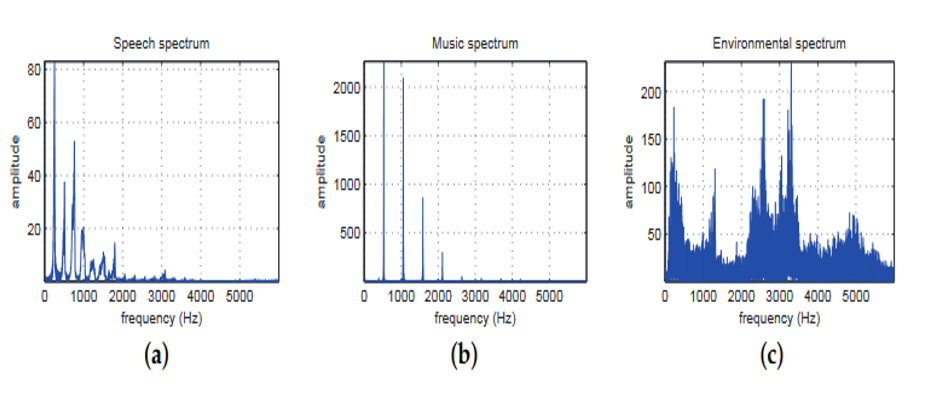
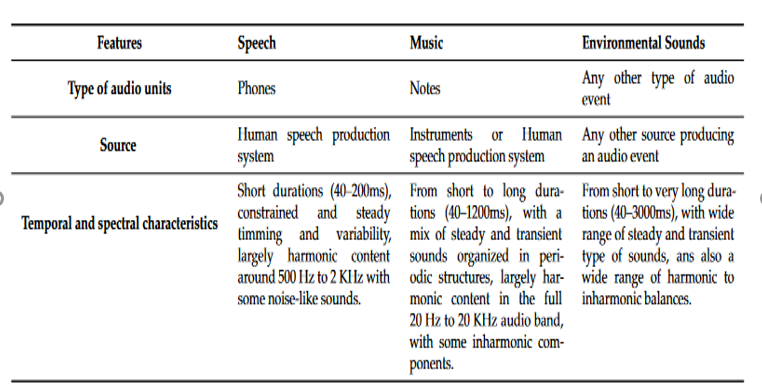
不同的发声源的频谱图是不一样的(可以理解成音色上不一样)
下面这几张图分别给出了语音、音乐和环境噪声的频域图像:
可能的去噪方法
- 线性滤波器
- 谱减法
- 语音降噪模型(RNNNoise, DPRNN)
特征提取
常见的特征提取会聚焦于这几个方面:
- 频谱特征
- 韵律特性:音高、语速和音色的变化
- 声音质量特征:粗糙度,颤声
- 基于Teager能量算子
MFCC(梅尔频率倒谱系数)
模拟人耳听到的声音:低频覆盖高频,音量大的覆盖音量小的
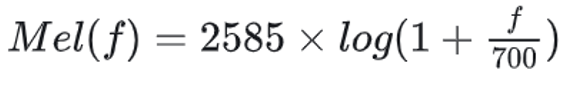
- 对音频信号进行傅里叶转换,得到信号的频谱
- 用梅尔滤波器组(一个模拟人耳频率感知的滤波器组)对频谱进行处理,产生梅尔频谱
- 取对数
- 最后进行离散余弦变换(Discrete Cosine Transform,DCT),得到梅尔频率倒谱系数。
6. 代码展示
GLAM
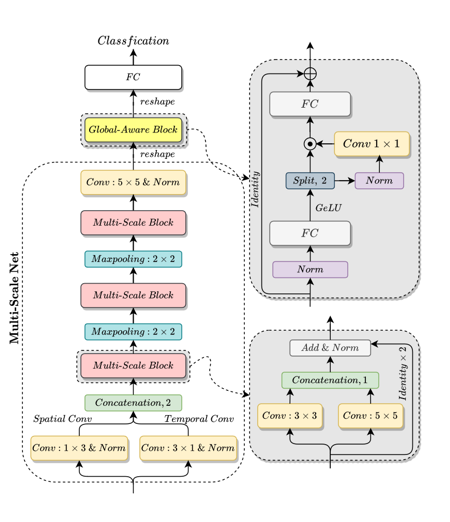
SPEECH EMOTION RECOGNITION WITH GLOBAL-AWARE FUSION ON MULTI-SCALE FEATURE REPRESENTATION
Deep Convolutional Neural Network and Gray Wolf Optimization Algorithm for Speech Emotion Recognition